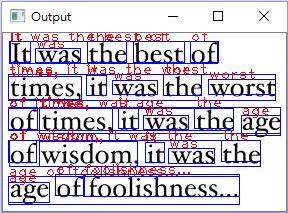
def text_rekognition(self, event = None):
client=boto3.client('rekognition')
img = cv2.imread(self.imageFile)
imOut = img
img_PIL = Image.open(self.imageFile)
width, height = img_PIL.size
with open(self.imageFile, 'rb') as image:
text_response = client.detect_text(Image={'Bytes': image.read()})
text_jsonfile = "textoutput.json"
with open(text_jsonfile, 'w') as fp:
json.dump(text_response, fp)
#i = 0
for text in text_response['TextDetections']:
#Rectangle The text BoundingBox
cv2.rectangle(imOut,
(int(width*text['Geometry']['BoundingBox']['Left']),
int(height*text['Geometry']['BoundingBox']['Top'])),
(int(width*(text['Geometry']['BoundingBox']['Left']+
text['Geometry']['BoundingBox']['Width'])),
int(height*(text['Geometry']['BoundingBox']['Top']+
text['Geometry']['BoundingBox']['Height']))),
self.color_1,
int(self.linesizespinbox.get()))
#print the text
cv2.putText(imOut,
text['DetectedText'],
(int(width*text['Geometry']['BoundingBox']['Left']),
int(height*text['Geometry']['BoundingBox']['Top'])),
self.fontcv2Var.get(),
int(self.fontsizespinbox.get()),
self.color_2,
int(self.linesizespinbox.get()),
self.fontlinetypecv2Var.get())
self.DisplaySceneMarkInfo.insert(tk.END,text['DetectedText']+'\n')
while True:
cv2.imshow("Output", imOut)
k = cv2.waitKey(0) & 0xFF
if k == 113:
break
cv2.destroyAllWindows()


 iThome鐵人賽
iThome鐵人賽